


Type Characteristics
| Symbol | Type Characteristic | description |
| d | directory | collection of files |
| l | link | link to the directory of a file |
| - | file | stream of data |
| c | character | a character device that passes/shares data char by char |
| b | block | a block device transfer data in big size of blocks |
| p | pipe | transfer one process input to another process output |
| s | socket | same as a pipe but handles more than one process |
Device Files
When you run the command ls -l /dev, you will see a list of all the device files on your system. The names of the device files will start with /dev/ and will be followed by the name of the device. The /dev directory contains device files that represent hardware devices, pseudo-devices, and interfaces to various system components. These device files allow interaction with hardware devices and provide access to system resources.
The devices can have different partitions like:
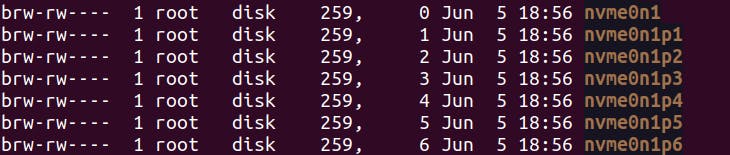
Pseudo devices: These devices are not physically connected to the system. These are char devices.

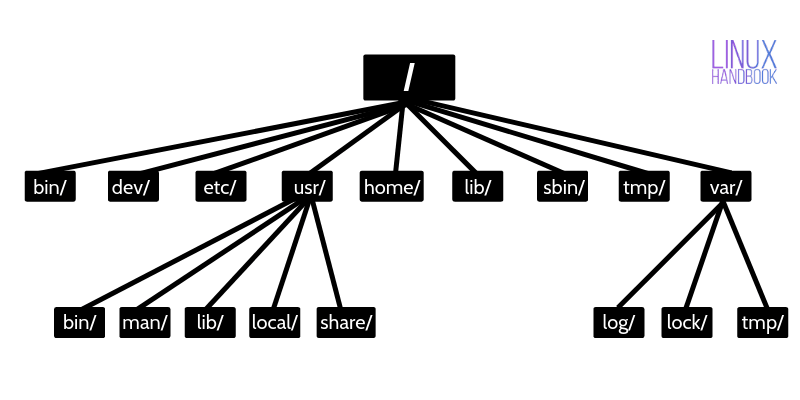
Filesystem Hierarchy
/ -> root directory
/bin -> contains essential & ready to run binaries
/boot -> contains bootloader files
/dev -> contains device files
/etc -> contains configuration files
/home -> home directory
/lib -> contains libraries
/mnt -> temp mounted FS
/opt -> optional software packages
/proc -> process info
/root -> home directory for root
/sbin -> system binaries which are run by the root
Journaling
Journaling is a technique used in file systems to ensure data consistency and improve recovery in the event of system crashes or power failures. It is particularly relevant in modern file systems like ext4 and XFS. Journaling helps minimize the risk of data corruption and file system inconsistencies caused by abrupt system interruptions. It improves the reliability and robustness of file systems by providing a mechanism for efficient recovery and maintaining data integrity.
Desktop File system types
| Desktop file types | Description |
| ext 4 | Latest & standard choice of file system which supports disk space of 1 exabyte and a file size of 16 TB |
| Btrfs | Butter/Better file system but it is not stable as other |
| XFS | A high-performance journaling file system generally good for servers |
| NTFS & FAT | windows file system |
| HFS | MAC file system |
To check the filesystem of Linux:-
df -T
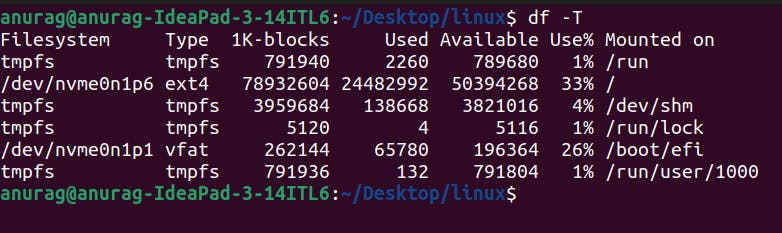
We can create multiple partitions in any disk and each partition acts as an individual block device. And each block system can act as a different filesystem.
Partition Table :
A partition table is a data structure that defines the layout of partitions on a storage device such as a hard disk drive (HDD) or solid-state drive (SSD). It provides the necessary information for the operating system to identify and access different regions of the storage device as separate partitions.
There are two main types of partition tables:
- Master Boot Record (MBR): MBR is the traditional partitioning scheme used on most legacy BIOS-based systems. It supports up to four primary partitions, or three primary partitions and one extended partition that can contain multiple logical partitions. The size of a single partition in MBR disk can only amount to 2TB. Therefore, the MBR-based partitioning scheme cannot meet the increasing needs.
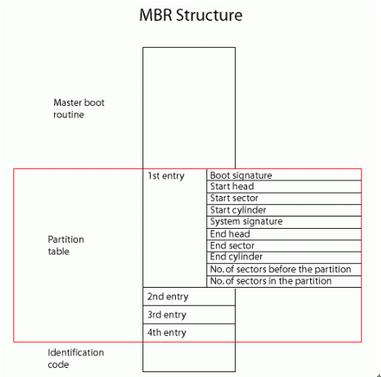
- GUID Partition Table (GPT): GPT is the modern partitioning scheme commonly used on newer systems with Unified Extensible Firmware Interface (UEFI). It supports larger disk sizes, allows an almost unlimited number of partitions, and provides more robust data integrity through redundancy and checksums.
File system structure
A file system structure defines how data is organized and stored on a storage device such as a hard disk drive or solid-state drive. It encompasses the hierarchy of directories (folders) and files, as well as the metadata associated with them.
FS has 4 major components
Bootblock: The boot block is a small portion of the file system reserved for storing the boot loader code. The boot block is typically located at the beginning of the partition or disk and plays a crucial role in the system boot process.
SuperBlock: The superblock is a crucial data structure at the beginning of the file system. It contains metadata about the file system, such as its type, size, block size, and other important parameters. The superblock serves as a reference point for accessing other components of the file system.
Inode table: An inode (index node) is a data structure that stores metadata about a file or directory. Each file or directory on the file system is associated with an inode, which contains information like permissions, ownership, timestamps, and pointers to the data blocks that hold the actual file contents.
Data Blocks: Data blocks are the units of storage where the actual file content is stored. File systems allocate one or more data blocks to hold the data associated with a file. The size of a data block can vary depending on the file system.
Inode
Inodes are index nodes in Linux file systems that act as a database-like structure managing files. Each file or directory has an associated inode, which contains all metadata about the file except its content and name. Inodes store information such as permissions, ownership, timestamps, file size, and pointers to the data blocks holding the file's actual data. Inodes are allocated space when the file system is created, ensuring efficient management of file metadata and data block pointers. They play a critical role in organizing files, managing permissions, and facilitating file operations within the file system.
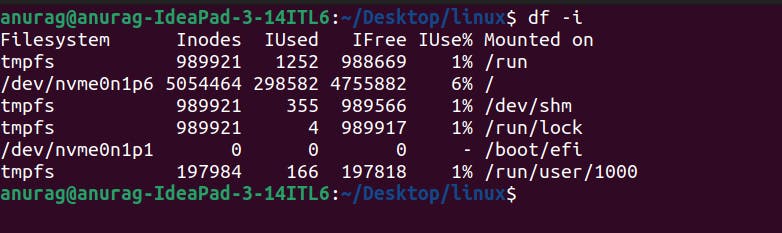
To check how many inodes are available:-
df -i
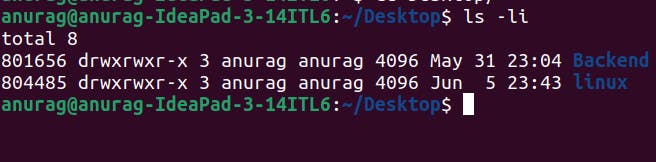
To check how many inodes are available in the current directory:-
ls -li
How do inodes work and locate files:
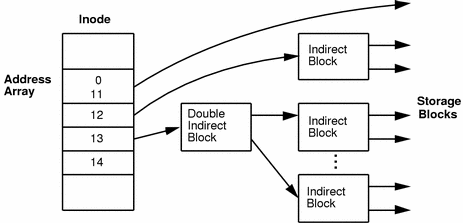
We know our data is out there on the disk somewhere, unfortunately, it probably wasn't stored sequentially, so we have to use inodes. Inodes point to the actual data blocks of your files. In a typical filesystem (not all work the same), each inode contains 15 pointers, and the first 12 pointers point directly to the data blocks. The 13th pointer points to a block containing pointers to more blocks, the 14th pointer points to another nested block of pointers, and the 15th pointer points yet again to another block of pointers! Confusing, I know! The reason this is done this way is to keep the inode structure the same for every inode but be able to reference files of different sizes. If you had a small file, you could find it quicker with the first 12 direct pointers, larger files can be found with the nests of pointers. Either way, the structure of the inode is the same.
Symlinks
In the Windows operating system, there are things known as shortcuts, shortcuts are just aliases to other files. If you do something to the original file, you could potentially break the shortcut. In Linux, the equivalent of shortcuts is symbolic links (or soft links or symlinks). Symlinks allow us to link to another file by its filename. Another type of link found in Linux is hard links, these are other files with a link to an inode.
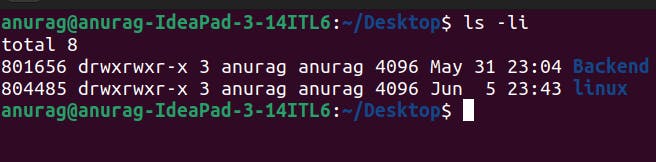
the third field here represents the hard link count.

Let's say you have a file named test1, and you create a symbolic link called soft1 that points to test1. Symbolic links, denoted by ->, are special files that act as references to other filenames. They do not have their unique inode numbers like regular files. Instead, they use the filenames they point to.
When you modify a symbolic link, the file it points to (in this case, test1) does modify. The symbolic link itself is simply updated to point to a different filename if you choose to change its target.
Inode numbers are unique within a single filesystem. You cannot have two files with the same inode number within the same filesystem. Therefore, you cannot reference a file in a different filesystem using its inode number.
Note:
if we make changes in the soft link file then "yes" they would be shown in the original file
if we make changes in the hard link file then "yes" they would be shown both the original and soft link file
if we delete the original file then the soft link doesn't work, but the hard link works properly
Creating a symlink
ln -s test1 soft1
To create a symbolic link, you use the ln command with -s for symbolic and you specific a target file and then a link name.
Creating a hardlink
ln test1 hard1
Similar to a symlink creation, except this time you leave out the -s.